MASS에 있는 Cars93 데이터를 dplyr package를 이용하여 처리해보도록 하겠습니다.
Cars93의 데이터 형태는 다음과 같습니다.
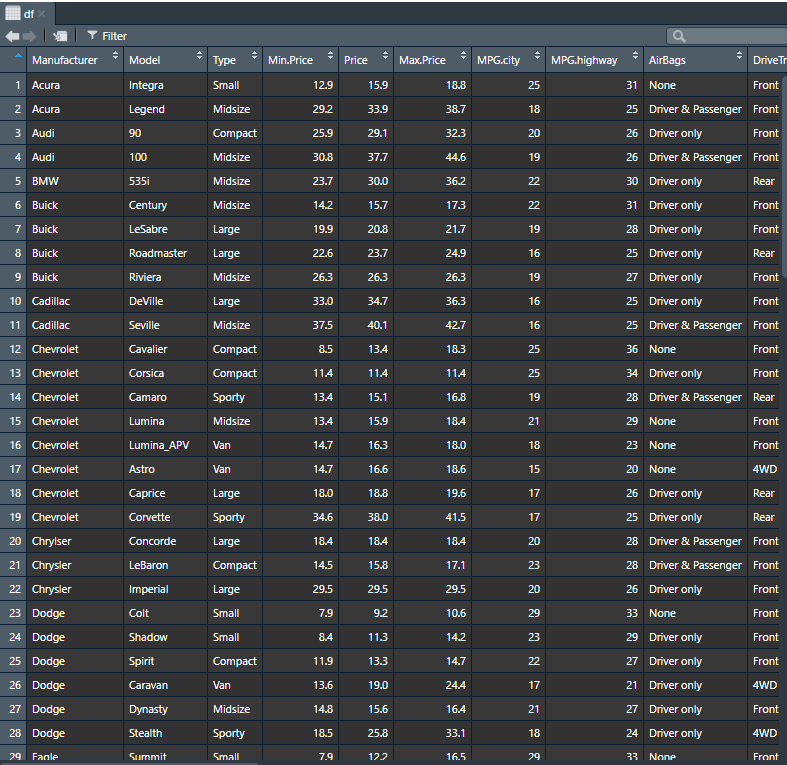
기본적으로 install.packages("패키지이름")을 이용하여 설치한다음 library를 이용하여 불러온다음 데이터의 기본적인 구조를 파악합니다.
> library(dplyr)
> library(MASS)
> df <- Cars93
> str(df) #자료의 구조파악
'data.frame': 93 obs. of 27 variables:
$ Manufacturer : Factor w/ 32 levels "Acura","Audi",..: 1 1 2 2 3 4 4 4 4 5 ...
$ Model : Factor w/ 93 levels "100","190E","240",..: 49 56 9 1 6 24 54 74 73 35 ...
$ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ...
$ Min.Price : num 12.9 29.2 25.9 30.8 23.7 14.2 19.9 22.6 26.3 33 ...
$ Price : num 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ...
$ Max.Price : num 18.8 38.7 32.3 44.6 36.2 17.3 21.7 24.9 26.3 36.3 ...
$ MPG.city : int 25 18 20 19 22 22 19 16 19 16 ...
$ MPG.highway : int 31 25 26 26 30 31 28 25 27 25 ...
$ AirBags : Factor w/ 3 levels "Driver & Passenger",..: 3 1 2 1 2 2 2 2 2 2 ...
$ DriveTrain : Factor w/ 3 levels "4WD","Front",..: 2 2 2 2 3 2 2 3 2 2 ...
$ Cylinders : Factor w/ 6 levels "3","4","5","6",..: 2 4 4 4 2 2 4 4 4 5 ...
$ EngineSize : num 1.8 3.2 2.8 2.8 3.5 2.2 3.8 5.7 3.8 4.9 ...
$ Horsepower : int 140 200 172 172 208 110 170 180 170 200 ...
$ RPM : int 6300 5500 5500 5500 5700 5200 4800 4000 4800 4100 ...
$ Rev.per.mile : int 2890 2335 2280 2535 2545 2565 1570 1320 1690 1510 ...
$ Man.trans.avail : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 1 1 1 1 ...
$ Fuel.tank.capacity: num 13.2 18 16.9 21.1 21.1 16.4 18 23 18.8 18 ...
$ Passengers : int 5 5 5 6 4 6 6 6 5 6 ...
$ Length : int 177 195 180 193 186 189 200 216 198 206 ...
$ Wheelbase : int 102 115 102 106 109 105 111 116 108 114 ...
$ Width : int 68 71 67 70 69 69 74 78 73 73 ...
$ Turn.circle : int 37 38 37 37 39 41 42 45 41 43 ...
$ Rear.seat.room : num 26.5 30 28 31 27 28 30.5 30.5 26.5 35 ...
$ Luggage.room : int 11 15 14 17 13 16 17 21 14 18 ...
$ Weight : int 2705 3560 3375 3405 3640 2880 3470 4105 3495 3620 ...
$ Origin : Factor w/ 2 levels "USA","non-USA": 2 2 2 2 2 1 1 1 1 1 ...
$ Make : Factor w/ 93 levels "Acura Integra",..: 1 2 4 3 5 6 7 9 8 10 ...
> dim(df) #행,열 수 파악
[1] 93 27
> distinct(df, Origin,Type)
Type Origin
1 Small non-USA
2 Midsize non-USA
3 Compact non-USA
4 Midsize USA
5 Large USA
6 Compact USA
7 Sporty USA
8 Van USA
9 Small USA
10 Sporty non-USA
11 Van non-USA1.자료추출하기 (sample_n, sample_frac)이용
dplyr를 이용하여 자료를 추출할 수있는데 sample_n을 이용하면 원하는 개수 만큼 추출할수있고 sample_frac을 이용하면 원하는 비율만큼 추출할수 있습니다.
> sample_n(df,10) #자료중 랜덤으로 10개 추출 //
Manufacturer Model Type Min.Price Price Max.Price MPG.city MPG.highway AirBags
1 Chevrolet Cavalier Compact 8.5 13.4 18.3 25 36 None
2 Geo Metro Small 6.7 8.4 10.0 46 50 None
3 Buick Roadmaster Large 22.6 23.7 24.9 16 25 Driver only
4 Buick Century Midsize 14.2 15.7 17.3 22 31 Driver only
5 Ford Crown_Victoria Large 20.1 20.9 21.7 18 26 Driver only
6 Geo Storm Sporty 11.5 12.5 13.5 30 36 Driver only
7 Nissan Maxima Midsize 21.0 21.5 22.0 21 26 Driver only
8 Chevrolet Corvette Sporty 34.6 38.0 41.5 17 25 Driver only
9 Chrylser Concorde Large 18.4 18.4 18.4 20 28 Driver & Passenger
10 Mazda 323 Small 7.4 8.3 9.1 29 37 None
DriveTrain Cylinders EngineSize Horsepower RPM Rev.per.mile Man.trans.avail Fuel.tank.capacity Passengers
1 Front 4 2.2 110 5200 2380 Yes 15.2 5
2 Front 3 1.0 55 5700 3755 Yes 10.6 4
3 Rear 6 5.7 180 4000 1320 No 23.0 6
4 Front 4 2.2 110 5200 2565 No 16.4 6
5 Rear 8 4.6 190 4200 1415 No 20.0 6
6 Front 4 1.6 90 5400 3250 Yes 12.4 4
7 Front 6 3.0 160 5200 2045 No 18.5 5
8 Rear 8 5.7 300 5000 1450 Yes 20.0 2
9 Front 6 3.3 153 5300 1990 No 18.0 6
10 Front 4 1.6 82 5000 2370 Yes 13.2 4
Length Wheelbase Width Turn.circle Rear.seat.room Luggage.room Weight Origin Make
1 182 101 66 38 25.0 13 2490 USA Chevrolet Cavalier
2 151 93 63 34 27.5 10 1695 non-USA Geo Metro
3 216 116 78 45 30.5 21 4105 USA Buick Roadmaster
4 189 105 69 41 28.0 16 2880 USA Buick Century
5 212 114 78 43 30.0 21 3950 USA Ford Crown_Victoria
6 164 97 67 37 24.5 11 2475 non-USA Geo Storm
7 188 104 69 41 28.5 14 3200 non-USA Nissan Maxima
8 179 96 74 43 NA NA 3380 USA Chevrolet Corvette
9 203 113 74 40 31.0 15 3515 USA Chrylser Concorde
10 164 97 66 34 27.0 16 2325 non-USA Mazda 323
> sample_n(df[,1:3],10) #자료중 랜덤으로 10개추출하되 1~3열만 추출
Manufacturer Model Type
1 Mercedes-Benz 190E Compact
2 Chrylser Concorde Large
3 Chevrolet Astro Van
4 Dodge Shadow Small
5 Mercury Capri Sporty
6 Oldsmobile Achieva Compact
7 Oldsmobile Cutlass_Ciera Midsize
8 Hyundai Excel Small
9 Ford Probe Sporty
10 Suzuki Swift Small
> sample_n(df[,1:3],20,replace=TRUE) #bootstrap으로 복원추출하는 경우 //defalut값은 비복원(FALSE)
Manufacturer Model Type
1 Chevrolet Lumina_APV Van
2 Plymouth Laser Sporty
3 Pontiac Grand_Prix Midsize
4 Ford Taurus Midsize
5 Chrylser Concorde Large
6 Chevrolet Corsica Compact
7 Nissan Altima Compact
8 Toyota Previa Van
9 Nissan Quest Van
10 Pontiac Sunbird Compact
11 Pontiac Sunbird Compact
12 Oldsmobile Eighty-Eight Large
13 Acura Legend Midsize
14 Ford Escort Small
15 Volkswagen Eurovan Van
16 Volvo 240 Compact
17 Geo Metro Small
18 Volkswagen Passat Compact
19 Dodge Spirit Compact
20 Acura Legend Midsize
> distinct(sample_n(df[,1:3],20,replace=TRUE)) #분명 20개를 추출하였는데 중복때문에 20개이하로나옴
Manufacturer Model Type
1 Audi 90 Compact
2 Audi 100 Midsize
3 Buick Century Midsize
4 Volkswagen Eurovan Van
5 Ford Aerostar Van
6 Chrysler LeBaron Compact
7 Plymouth Laser Sporty
8 Mazda Protege Small
9 Mazda MPV Van
10 Nissan Altima Compact
11 Nissan Maxima Midsize
12 Buick Roadmaster Large
13 Ford Probe Sporty
14 Lexus SC300 Midsize
15 Chevrolet Lumina_APV Van
16 Dodge Caravan Van
17 Dodge Stealth Sporty
18 Dodge Colt Small
> sample_frac(df,0.1) # 랜덤으로 0.1 만큼 추출 -> 9개추출됨
Manufacturer Model Type Min.Price Price Max.Price MPG.city MPG.highway AirBags
1 Acura Legend Midsize 29.2 33.9 38.7 18 25 Driver & Passenger
2 Chevrolet Caprice Large 18.0 18.8 19.6 17 26 Driver only
3 Geo Metro Small 6.7 8.4 10.0 46 50 None
4 Dodge Shadow Small 8.4 11.3 14.2 23 29 Driver only
5 BMW 535i Midsize 23.7 30.0 36.2 22 30 Driver only
6 Lincoln Continental Midsize 33.3 34.3 35.3 17 26 Driver & Passenger
7 Oldsmobile Eighty-Eight Large 19.5 20.7 21.9 19 28 Driver only
8 Chevrolet Lumina Midsize 13.4 15.9 18.4 21 29 None
9 Mazda MPV Van 16.6 19.1 21.7 18 24 None
DriveTrain Cylinders EngineSize Horsepower RPM Rev.per.mile Man.trans.avail Fuel.tank.capacity Passengers
1 Front 6 3.2 200 5500 2335 Yes 18.0 5
2 Rear 8 5.0 170 4200 1350 No 23.0 6
3 Front 3 1.0 55 5700 3755 Yes 10.6 4
4 Front 4 2.2 93 4800 2595 Yes 14.0 5
5 Rear 4 3.5 208 5700 2545 Yes 21.1 4
6 Front 6 3.8 160 4400 1835 No 18.4 6
7 Front 6 3.8 170 4800 1570 No 18.0 6
8 Front 4 2.2 110 5200 2595 No 16.5 6
9 4WD 6 3.0 155 5000 2240 No 19.6 7
Length Wheelbase Width Turn.circle Rear.seat.room Luggage.room Weight Origin Make
1 195 115 71 38 30.0 15 3560 non-USA Acura Legend
2 214 116 77 42 29.5 20 3910 USA Chevrolet Caprice
3 151 93 63 34 27.5 10 1695 non-USA Geo Metro
4 172 97 67 38 26.5 13 2670 USA Dodge Shadow
5 186 109 69 39 27.0 13 3640 non-USA BMW 535i
6 205 109 73 42 30.0 19 3695 USA Lincoln Continental
7 201 111 74 42 31.5 17 3470 USA Oldsmobile Eighty-Eight
8 198 108 71 40 28.5 16 3195 USA Chevrolet Lumina
9 190 110 72 39 27.5 NA 3735 non-USA Mazda MPV
> df[,c("Origin","RPM","Model")] %>% group_by(Origin) %>% sample_n(5) #원하는 colum을 Origin기준 그룹으로 각 5개씩 랜덤 추출
# A tibble: 10 x 3
# Groups: Origin [2]
Origin RPM Model
<fct> <int> <fct>
1 USA 5000 Festiva
2 USA 5200 Sunbird
3 USA 5600 LeMans
4 USA 4000 Roadmaster
5 USA 6000 Stealth
6 non-USA 5600 Altima
7 non-USA 5000 Previa
8 non-USA 5200 Loyale
9 non-USA 5000 MPV
10 non-USA 5900 Civic 2.새로운 변수 추가하기(새로운 변수생성 mutate, transmute)
mutate는 기존의 열에 신규변수를추가하지만 transmute는 기존의 열을 날리고 신규변수만 남습니다.
> df_1 <- df[1:10,c("Model", "Min.Price", "Max.Price")] #순서대로 1행부터 10행, 3개 colum 추출
> df_1 %>% mutate(df_1,
+ Price_range=Max.Price-Min.Price,
+ Price_mean=(Max.Price+Min.Price)/2) #가격의 범위와 평균구하기
Model Min.Price Max.Price Price_range Price_mean
1 Integra 12.9 18.8 5.9 15.85
2 Legend 29.2 38.7 9.5 33.95
3 90 25.9 32.3 6.4 29.10
4 100 30.8 44.6 13.8 37.70
5 535i 23.7 36.2 12.5 29.95
6 Century 14.2 17.3 3.1 15.75
7 LeSabre 19.9 21.7 1.8 20.80
8 Roadmaster 22.6 24.9 2.3 23.75
9 Riviera 26.3 26.3 0.0 26.30
10 DeVille 33.0 36.3 3.3 34.65
> df_2 <- transmute(df_1,
+ Price_range=Max.Price-Min.Price,
+ Price_mean=(Max.Price+Min.Price)/2)
> df_2
Price_range Price_mean
1 5.9 15.85
2 9.5 33.95
3 6.4 29.10
4 13.8 37.70
5 12.5 29.95
6 3.1 15.75
7 1.8 20.80
8 2.3 23.75
9 0.0 26.30
10 3.3 34.653. 통계값 계산 (summarise)
> ##통계값 계산 (summarise)
> summary(df$Price,na.rm=TRUE) #방법 1 dplyr 사용x
Min. 1st Qu. Median Mean 3rd Qu. Max.
7.40 12.20 17.70 19.51 23.30 61.90
> summarise(df,
+ Price_mean=mean(Price,na.rm=TRUE),
+ Price_median=median(Price,na.rm=TRUE),
+ Price_sd=sd(Price,na.rm=TRUE),
+ Price_min=min(Price,na.rm=TRUE),
+ Price_max=max(Price,na.rm=TRUE),
+ Price_mean=mean(Price,na.rm=TRUE),
+ Price_IQR=IQR(Price,na.rm=TRUE),
+ Price_sum=sum(Price,na.rm=TRUE),
+ tot_cnt=n(),
+ Manufacturer_dist_cnt=n_distinct(Manufacturer),
+ First_obs=first(Manufacturer),
+ Last_obs=last(Manufacturer),
+ Nth_3th_obs=nth(Manufacturer,5)) #방법 2 dplyr 사용o
Price_mean Price_median Price_sd Price_min Price_max Price_IQR Price_sum tot_cnt Manufacturer_dist_cnt
1 19.50968 17.7 9.65943 7.4 61.9 11.1 1814.4 93 32
First_obs Last_obs Nth_3th_obs
1 Acura Volvo BMW
> #그룹별 통계량 계산
> df %>% group_by(Type) %>%
+ summarise(tot_cnt=n(),
+ Manufacturer_dist_cnt=n_distinct(Manufacturer),
+ Price_mean=mean(Price,na.rm=TRUE),
+ Price_sd=sd(Price,na.rm=TRUE))
# A tibble: 6 x 5
Type tot_cnt Manufacturer_dist_cnt Price_mean Price_sd
* <fct> <int> <int> <dbl> <dbl>
1 Compact 16 15 18.2 6.69
2 Large 11 10 24.3 6.34
3 Midsize 22 20 27.2 12.3
4 Small 21 16 10.2 1.95
5 Sporty 14 12 19.4 7.97
6 Van 9 8 19.1 1.88여기서 tot_cnt와 Manufacturer_dist_cnt의 개수가 다른이유는 filter를 이용하여 알수있는데 자세한filter사용방법은 다음시간에 다루기로 합니다.
Type이 Compact인 데이터 추출결과 총 16개가 나오는데 2,3행을 보면 Manufacturer과 Type가 겹쳐 15개로 계산된걸 알수있습니다.
> df %>% group_by(Type,Manufacturer) %>% filter(Type=="Compact")
# A tibble: 16 x 27
# Groups: Type, Manufacturer [15]
Manufacturer Model Type Min.Price Price Max.Price MPG.city MPG.highway AirBags DriveTrain Cylinders
<fct> <fct> <fct> <dbl> <dbl> <dbl> <int> <int> <fct> <fct> <fct>
1 Audi 90 Comp~ 25.9 29.1 32.3 20 26 Driver~ Front 6
2 Chevrolet Cava~ Comp~ 8.5 13.4 18.3 25 36 None Front 4
3 Chevrolet Cors~ Comp~ 11.4 11.4 11.4 25 34 Driver~ Front 4
4 Chrysler LeBa~ Comp~ 14.5 15.8 17.1 23 28 Driver~ Front 4
5 Dodge Spir~ Comp~ 11.9 13.3 14.7 22 27 Driver~ Front 4
6 Ford Tempo Comp~ 10.4 11.3 12.2 22 27 None Front 4
7 Honda Acco~ Comp~ 13.8 17.5 21.2 24 31 Driver~ Front 4
8 Mazda 626 Comp~ 14.3 16.5 18.7 26 34 Driver~ Front 4
9 Mercedes-Be~ 190E Comp~ 29 31.9 34.9 20 29 Driver~ Rear 4
10 Nissan Alti~ Comp~ 13 15.7 18.3 24 30 Driver~ Front 4
11 Oldsmobile Achi~ Comp~ 13 13.5 14 24 31 None Front 4
12 Pontiac Sunb~ Comp~ 9.4 11.1 12.8 23 31 None Front 4
13 Saab 900 Comp~ 20.3 28.7 37.1 20 26 Driver~ Front 4
14 Subaru Lega~ Comp~ 16.3 19.5 22.7 23 30 Driver~ 4WD 4
15 Volkswagen Pass~ Comp~ 17.6 20 22.4 21 30 None Front 4
16 Volvo 240 Comp~ 21.8 22.7 23.5 21 28 Driver~ Rear 4 tip
ctrl+shift+c 누르면 주석처리
# 1번 df_1 %>% mutate(df_1,
# Price_range=Max.Price-Min.Price,
# Price_mean=(Max.Price+Min.Price)/2)
#
#
# 2번 df_1 <- mutate(df_1,
# Price_range=Max.Price-Min.Price,
# Price_mean=(Max.Price+Min.Price)/2)
1번 방식으로 하면 df_1에 자료가 할당되지는 않지만 바로 결과값을 볼수 있고 2번방식은 할당이 바로되며 결과값도 바로볼수있다.
'R' 카테고리의 다른 글
| R 버전 확인 및 변경하기 (다운그레이드,업그레이드) (0) | 2021.04.07 |
|---|---|
| Randomforest로 사이영 상 수상 예측하기 (0) | 2021.04.06 |
| ggplot2를 이용한 시각화 ② (회귀선표시, 회귀분석, 범례표시) (0) | 2021.04.05 |
| ggplot2를 이용한 시각화 ① (두변수가연속형인경우, 그룹별 표시하기) (0) | 2021.04.05 |
| DPLYR를 이용한 Cars93처리 ② (0) | 2021.04.05 |